The court reporting industry generates over $1.5 billion in annual revenue globally and is projected to reach $2.27 billion by 2032. In the U.S. alone, the legal transcription market is valued at $2.62 billion and growing at 6.9% annually. This is not a niche. It is a massive, essential segment of the legal system, and it is under enormous strain.
A decade-long shortage of stenographers has left courtrooms without verbatim records, stalled depositions, and created a widening gap between the volume of legal proceedings and the capacity to document them. Firms that once relied solely on stenography are now adopting digital reporting, AI transcription, and remote workflows to keep up. The 2025 Court Reporting Industry Trends Report from AAERT describes it plainly: the profession's sustainability depends on technology adoption.
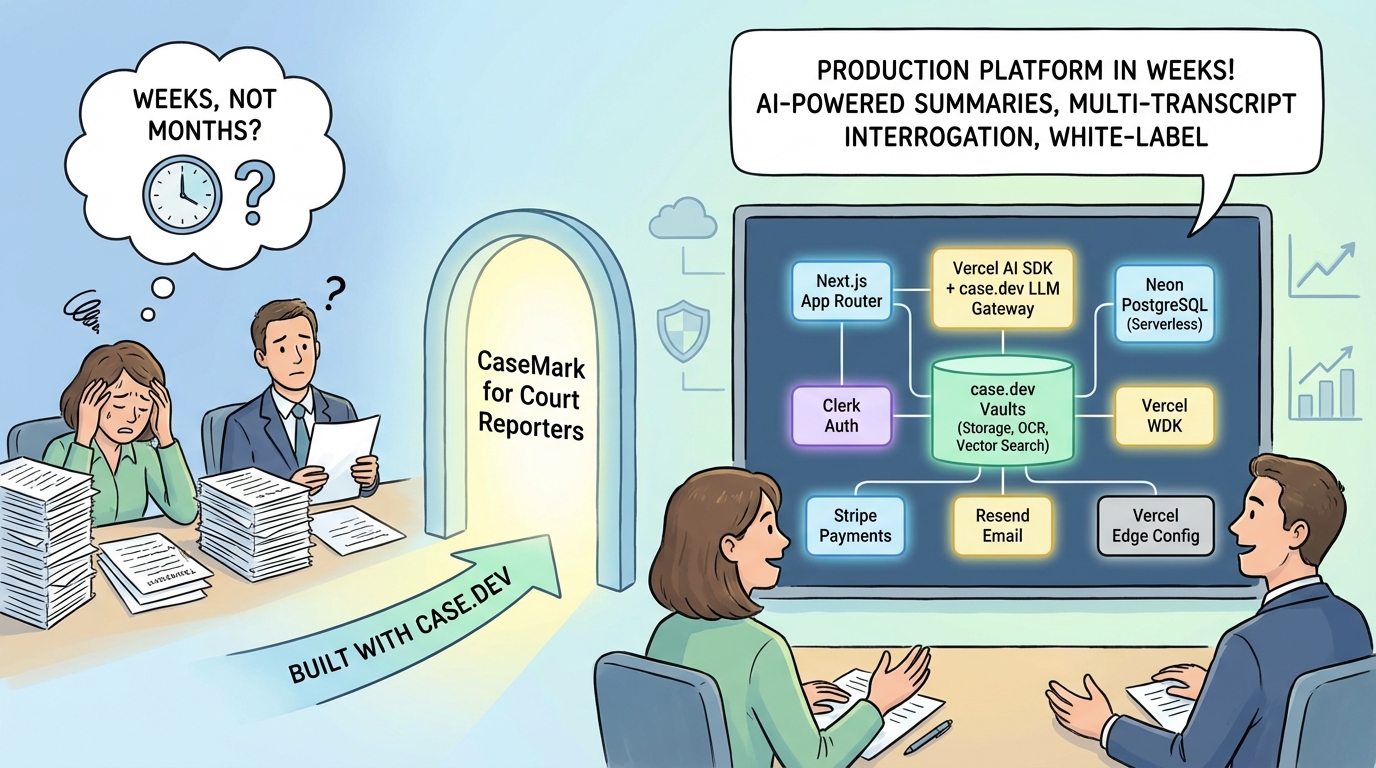
We saw an opportunity to build something that would help these firms. Not in six months. In weeks. CaseMark for Court Reporters is now generally available, and it was built entirely on top of case.dev.
The Problem: Transcripts Are an Underutilized Asset
Court reporting firms produce transcripts. That is the core of their business. But the value chain ends at delivery. Attorneys receive a transcript and then spend hours (or hire associates to spend hours) reading, summarizing, and extracting the information they actually need.
Firms have been leaving money on the table. What if the court reporter could deliver not just the transcript, but a deposition summary, a medical chronology, a trial digest, all with precise page-and-line citations, in minutes instead of days?
That is what CaseMark for Court Reporters does. And that is why the platform needed to be built fast. The market was ready. The firms were asking for it.
Why case.dev Made This Possible
Building a production-grade legal AI platform from scratch would normally require assembling a constellation of services: document storage, OCR, vector search, LLM orchestration, embeddings, transcription, authentication, payments, email delivery, and custom domain management. Each of those is a project in itself. Together, they represent months of integration work.
case.dev collapses that into a single platform. Here is what we used:
Document Vaults
Every transcript uploaded to CaseMark goes into a case.dev Vault: encrypted document storage with automatic OCR text extraction and semantic indexing. The Vault handles the entire pipeline from raw PDF to searchable, embeddings-ready content. No separate OCR service. No vector database to manage. No indexing pipeline to build.
AI Models Through a Single Endpoint
CaseMark runs 22+ specialized legal summary workflows. Each one sends transcript content to AI models through case.dev's unified LLM gateway. We use Claude from Anthropic for multi-transcript interrogation and various models for different summary types. Switching models or adding new ones requires changing a single parameter, not rebuilding an integration.
Hybrid RAG Search
The multi-transcript interrogation feature (where users ask questions across up to 50 documents simultaneously) uses case.dev's hybrid search combining vector similarity and keyword matching. When a user asks "find contradictions between Smith's and Jones's testimony," the system retrieves relevant passages from across all selected documents, scoped precisely to those files, and synthesizes an answer with page-and-line citations.
Production Infrastructure
case.dev provides the encryption, tenant isolation, and compliance posture that legal applications require. Data encrypted at rest with AES-256. TLS 1.3 in transit. Documents never used for AI training. SOC 2 Type II audited. HIPAA compliant. We did not have to build any of this.
What We Built in Weeks
With case.dev handling the infrastructure layer, our engineering team focused on the product:
-
22+ legal summary workflows. Deposition analysis, page-line summaries, narrative summaries, medical chronologies, trial digests, arbitration summaries, hearing summaries, and more. Each purpose-built for specific transcript types.
-
Multi-transcript interrogation. A conversational interface where users select documents and ask questions in natural language. The AI searches across all selected transcripts, returns cited answers, and maintains conversation context. Users can find contradictions, build timelines, generate cross-examination questions, and identify key admissions.
-
100% white-label platform. Every firm gets a branded portal with their logo, colors, custom domain, and email sending domain. We integrated BrandFetch to auto-detect firm branding from their website URL. A new firm's portal is live in under five minutes.
-
Flexible billing. Pay-as-you-go for firms testing the platform, flat monthly plans for steady volume, enterprise pricing for high-volume operations. All powered by Stripe with usage tracking and invoice management.
-
Secure sharing and delivery. Password-protected share links with email verification, view tracking, download controls, expiration dates, and an approval workflow. External viewers (attorneys) see the firm's branded portal.
-
Matter management. Case-based organization with document grouping, activity tracking, and archiving.
The Technical Stack
For those interested in the architecture:
| Layer | Technology |
|---|---|
| Framework | Next.js (App Router) |
| AI | Vercel AI SDK + case.dev LLM gateway (Claude, GPT-4o, CaseMark Core 1) |
| Database | Neon PostgreSQL (serverless) + Drizzle ORM |
| Auth | Clerk (multi-org, satellite domains) |
| Documents | case.dev Vaults (storage, OCR, vector search) |
| Workflows | Vercel WDK (durable document processing) |
| Payments | Stripe (subscriptions + metered billing) |
| Resend + React Email | |
| Edge Routing | Vercel Edge Config (sub-10ms tenant resolution) |
| Deployment | Vercel |
The entire application runs on serverless infrastructure. No servers to manage. No scaling decisions to make. Tenant resolution happens at the edge in under 10 milliseconds.
Why This Matters for the Industry
The court reporting industry is at an inflection point. The U.S. Department of Labor reported only a 2% increase in court reporting jobs between 2014 and 2024, while demand for transcription services continued to climb. Graduation rates from stenography programs have dropped sharply. Experienced reporters are retiring faster than new ones enter the profession.
Firms that survive and grow in this environment will be the ones that extract more value from every transcript they produce. AI-powered summaries turn a transcript, a commodity work product, into a premium, revenue-generating deliverable. Multi-document interrogation gives litigation support teams capabilities that would have required a team of paralegals and days of work.
The firms using CaseMark today are already offering same-day deposition summaries, selling AI-powered analysis as a premium add-on, and differentiating themselves in a market where most competitors still deliver raw transcripts and nothing else.
What case.dev Enables
CaseMark for Court Reporters is a proof point for what case.dev makes possible. A small engineering team built a production-grade, multi-tenant, AI-powered legal platform with enterprise security, white-labeling, and flexible billing in weeks instead of months.
The court reporting industry needed this yesterday. Because case.dev handled the infrastructure, we could deliver it today.
If you are building for legal, case.dev is the foundation that lets you move at the speed the market demands.
CaseMark for Court Reporters is available now at casemark.com/partners/court-reporting.
Start building on case.dev at case.dev.
